I needed to PoC a solution for SSH users that are backed by an IdP but ran into some issues.
EC2 Instance Connect (IMO) seems to be way under promoted by AWS, and I feel like that’s a real disservice if you need (I’m so sorry for you) SSH (I do for this case).
The TLDR for ec2 instance connect:
- A user makes a call
aws ec2-instance-connect send-ssh-public-key --instance-id i-08e2c277f1ea9a99a --instance-os-user marcus.young --ssh-public-key file:///home/myoung/.ssh/asdf.pub - AWS pushes the public key to
http://169.254.169.254/latest/meta-data/managed-ssh-keys/active-keys/marcus.youngfor60seconds - The user does
ssh -i {private key that matches the public key} marcus.young@{public ip of the instance}and gets in.
That’s crazy cool, but we have a few issues outright (major ones):
- You can impersonate. There’s nothing keeping me from doing
--instance-os-user not.meand getting in. Fine in small cases bad for observability. You could tie this back to a user but that sucks. Youd have to tie back theSendSSHPublicKeycloudtrail call with the iam user/role via the request params to the box, and if youre not shipping auth.log youre screwed. If 100 people do this at once you’ve lost. There’s no way to see which key material let who in to run what. If you thought “Oh I’ll use sts principaltags” I love you. Keep reading. - Users have to exist ahead of time. This is the big one. If you thought “What if we create them when they send they create the key on the host”. You can’t. Not easily anyway. If you think it’s still solvable or said “What about NSS” keep reading homie.
- There’s no documented rate limits. I’ve brought this up, no answer yet. I might see if I can break this ;)
- You cannot directly do this to private instances. You’ll need public instances or bastions to do this. I’ll give you a snippet for that too.
Let’s get started.
First we need to bring up an Okta with IAM identity center.
Sorry peeps but if you think I’m doing that walkthrough just ctrl+w and touch grass. Not happening.
Let’s assume you have a working IdP and you can get into AWS. Let’s start there.
So impersonation….
The answer here is an SCP and sts principalTags.
For the principal tags, it’s sort of straight forward. Unless you discover an IAM identity center bug like I did.
If you’re using IAM identity center: You’ll need to use
https://aws.amazon.com/SAML/Attributes/AccessControl:{ attr name}
in Okta.
The bug? Do not use both AccessControl and PrincipalTag. Apparently the IdC freaks out during the SAML jank and wont do anything.
So in Okta, add this:
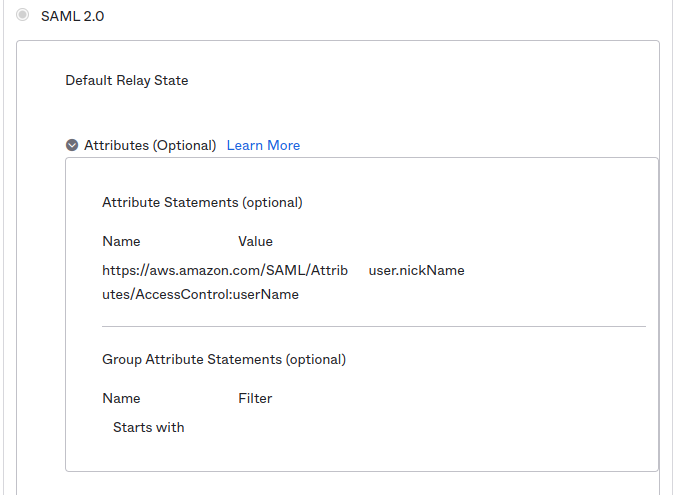
Also while you’re add it make sure you’re using the nickName for the username.
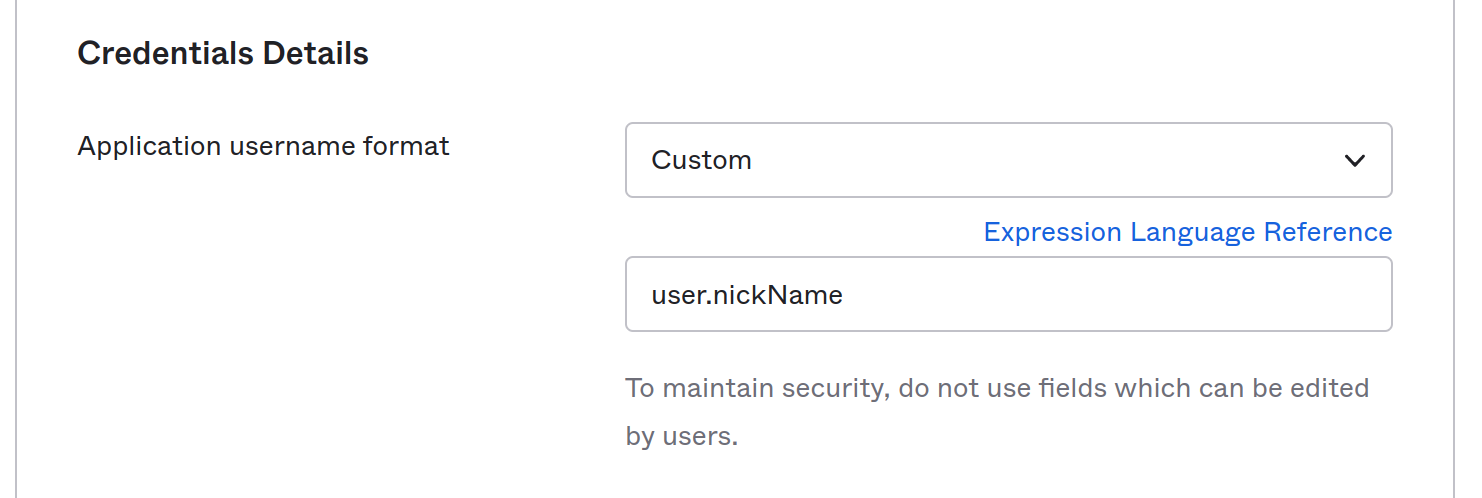
At this point go ahead and measure success by making sure that your user is in the first.last format and your AssumeRoleWithSAML call in Cloudtrail has the principalTags on the requestParameters. And by that I mean get angry and weep for 8 hours then find out you’re hitting an invisible AWS bug. I’ll wait.
Thanks for coming back.
Your user doesn’t have to be in this format but it tracks with my needs and my SCP as well as my janky NSS code. Modify it if you need. You do you.
1 2 3 4 5 6 7 8 9 10 | |
OK. Now that you’re getting the metadata lets lock it down.
We’re going to apply this SCP:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Very cool right?
What we’ve done now is said “Any call to SendSSHPublicKey has to have a --instance-os-user param that matches your userName principalTag that was set by okta
Prove it:
1 2 3 4 5 6 7 8 | |
1 2 3 4 5 6 7 8 9 10 11 | |
Bam. Now you can’t straight up ssh as others outright.
OK that part’s done, but we still have another blocker: the user has to exist first. That sucks if you have a thousand users. I don’t know about you but I don’t want to have to sit there and crawl Okta for users that may never ssh in.
OK So the way ec2-instance-connect software works (remember above about what SendSSHPublicKey does and ends it to the metadata endpoint):
- It adds some
AuthorizedKeysCommandlines to/etc/ssh/sshd_config - When A user tries to SSH in and fails first it will then hit
http://169.254.169.254/latest/meta-data/managed-ssh-keys/active-keys/{user name} - SSH Requires that user to exist. If it does, and the public key in memory from the metadata endpoint matches their private key: all good come on in bro
So we can’t rely on crawling, we can’t rely on ssh, but we can rely on nss since thats what ssh relies on for passwd.
OK so I sound like an expert but I’m not. A large chunk of this was hacked out by another person at work, but I’m familiar enough. Don’t lose hope in me yet.
So SSH talks to NSS. We can hook into NSS to do some logic and create a user like this
So now in my user-data I have this sin:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
I basically compile my nss garbage and add create files to passwd in /etc/nsswitch.conf
This means that when a user attempts to SSH it will hook in my C code that calls a script
That script does a
curl http://169.254.169.254/latest/meta-data/managed-ssh-keys/active-keys/{user name}.
If it gets a 200-300 code (the user has put a public key in there - remember this only works for 60s) then it will create the user.
After create I still have files so that SSH will go back and look them back up in /etc/passwd. So assuming they ran the aws ec2-instance-connect send-ssh-public-key command then tried to ssh within 60 seconds: they’ll have a user with a matching public key and they’ll get in.
Bonus: we should be able to do this to get into private instances.
For this proof I’m going to assume you have a public instance 1.2.3.4 and a private instance you want to reach 10.0.0.50
Let’s make your ~/.ssh/config file look like this:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Let’s jump to that private-vps by using the my-bastion as a jump host.
Hint: You’ll need to make 2 SendSSHPublicKey calls. One to the public (so you can get into it) and one to the private (so you can also get into it)
First let’s prove we can’t just get in. So you know I ain’t lyin.
1 2 3 4 5 6 7 | |
Told you. Let’s push the key to both. (remember you have 60s. obviously id write a tool for this later).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
Very cool. So what did we accomplish?
- New instances have absolutely zero requirements on anything other than that very early PoC libnss module. Ideally I could package that up.
- We have the normal SSH auditing story. auth.log lines up. We have cloudtrail logs that tell us people are ssh’ing in and where.
- We have JIT users.
- We use the same IAM stories for ssh. If I have 8 accounts I know that you need access to an AWS account to get to the instances into it. We could go further and add more principal tags to say that you can’t do sudo unless you have a tag, or that you can’t ssh at all if you don’t have a certain department. This is leagues better than some of the paid software I’ve tested.
- We increased no load to any custom tooling. Teleport has etcd, an SSH CA has some unique problems to solve, etc.
- Our onboarding and offboarding story for ssh is now the same as IAM
- In an incident etc we can simply block SendSSHPublicKey for suspicious users and
pkillsshd for the named user (a win over shared users) on the bastion and effectively kill them off everywhere.











































 ]]>
]]>
























































{kind=link}
{kind=link}